卷积通道竞争学习 (CwC) 算法部署笔记
该算法通过通道维度的竞争机制实现完全无反向传播的卷积网络训练。其核心思想是将特征图划分为类别相关的通道组,通过最大化目标类别的激活强度来引导网络自主学习特征,摆脱了对全局梯度和负样本生成的依赖。
1. 算法部署框架
1.1 核心架构:CFSE Block
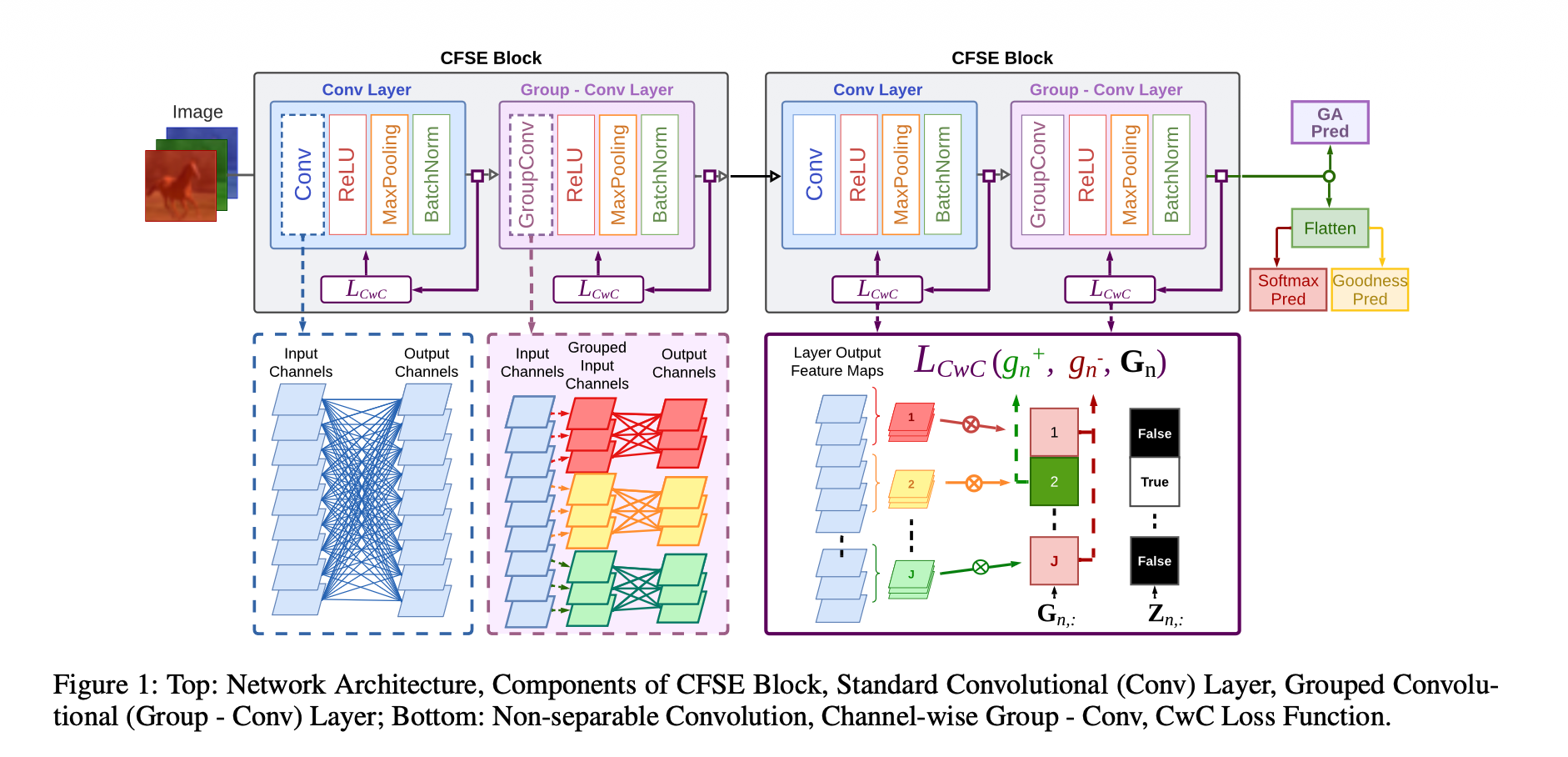
网络由多个 CFSE (Convolutional Feature Space Separation and Extraction) 模块堆叠而成。每个模块包含两层卷积操作,旨在逐步分离特征空间。
1 | 输入 X |
关键变量定义:
- $J$:目标类别的总数
- $C_{in}, C_{out}$:每一层的输入与输出通道数
- $S$:单个类别的通道组大小,计算为 $S = C_{in}/J$ 或 $S = C_{out}/J$
- $x_j, \hat{y}_j$:第 $j$ 个类别的输入和输出特征子集
- $\hat{S}_j$:第 $j$ 个类别的专家卷积核权重
2. 详细算法流程
第一步:特征子集划分 (Channel Partitioning)
将输入特征图 $Y \in \mathbb{R}^{N \times C \times H \times W}$ 沿通道维度切割成 $J$ 个独立子集。
- 每个子集 $\hat{Y}_j \in \mathbb{R}^{N \times S \times H \times W}$ 的通道大小为 $S$
第二步:计算专家输出 (Expert Computation)
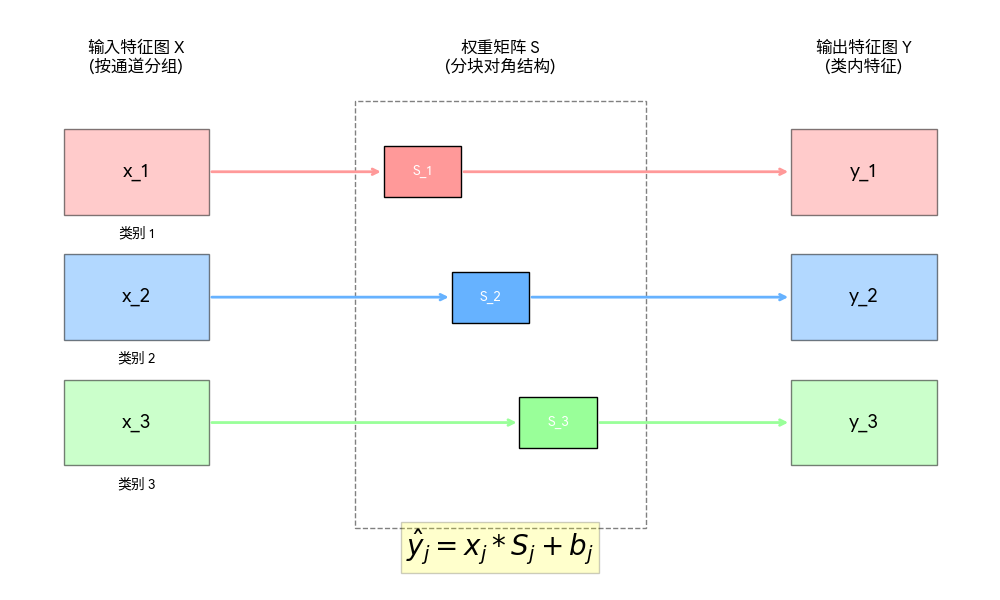
在 GroupConv 层中,每一组输入只与对应的专家核运算,其本质是分块对角矩阵运算:
注意:该步结构上实现了物理隔离,确保特征提取的专业性,同时大幅减少了参数量。
第三步:优度评估 (Goodness Formulation)
计算每一类通道组的”优度”分值 $G_{n,j}$,代表该层对第 $j$ 类的响应强度:
第四步:通道竞争损失计算 (CwC Loss)
利用 Softmax 机制在通道间引入竞争,不再需要生成负样本:
提取正优度 $g_n^+$:通过掩码矩阵从 $\mathbf{G}$ 中获取对应样本真实标签 $z_n$ 的列分值
定义二值标签掩码 $\mathbf{Z} \in \{0, 1\}^{N \times J}$,其中:
正优度计算:$\mathbf{g}^+ = \mathbf{G} \cdot \mathbf{Z}^T$
- 负优度计算:$\mathbf{g}^- = \mathbf{G} \cdot (\mathbf{1} - \mathbf{Z}^T)$
- 计算 $L_{CwC}$:
该函数强制模型增加正确类别的置信度,同时抑制错误类别的得分。
3. 训练策略:ILT (交错层训练)
为了实现高效部署,采用 ILT (Interleaved Layer Training) 策略代替全局 BP:
- 并行初始化:所有 CFSE 层同时启动训练,不进行梯度跨层回传
- 局部更新:每一层仅根据自身的 $L_{CwC}$ 产生的梯度更新本层参数
- 分步冻结:
- 监测每一层的性能表现
- 当某一层性能达到平台期(Plateau)时,停止该层权重更新
- 冻结后的层为后续层提供稳定且经过精炼的特征输出
4. 算法原理解析
- 通道即类别:CwC 强制将神经网络的通道与特定的语义类别挂钩。通过 $L_{CwC}$ 的约束,模型学会在看到特定物体时,让对应的通道组产生最强的激活。
- 空间与语义分离:标准卷积层用于学习联合特征,而分组卷积层则专门提取类内特征并划分类别空间。
- 高效与透明:分组卷积显著降低了计算开销。由于每一层都能独立分类,这种架构具有极高的透明度,方便观察模型对各维度的响应情况。
部署建议:在推理阶段,若追求极致轻量化,可选用 GA-pred (全局平均预测器) 直接根据最后一层的优度值分布输出类别,无需任何复杂的全连接层。