Synergistic Information Distillation (SID)
该算法通过协同信息蒸馏实现完全无反向传播的模块化训练,核心思想是将深度网络分解为多个独立优化的模块,每个模块通过局部目标函数逐步精炼”信念分布”。
网络架构
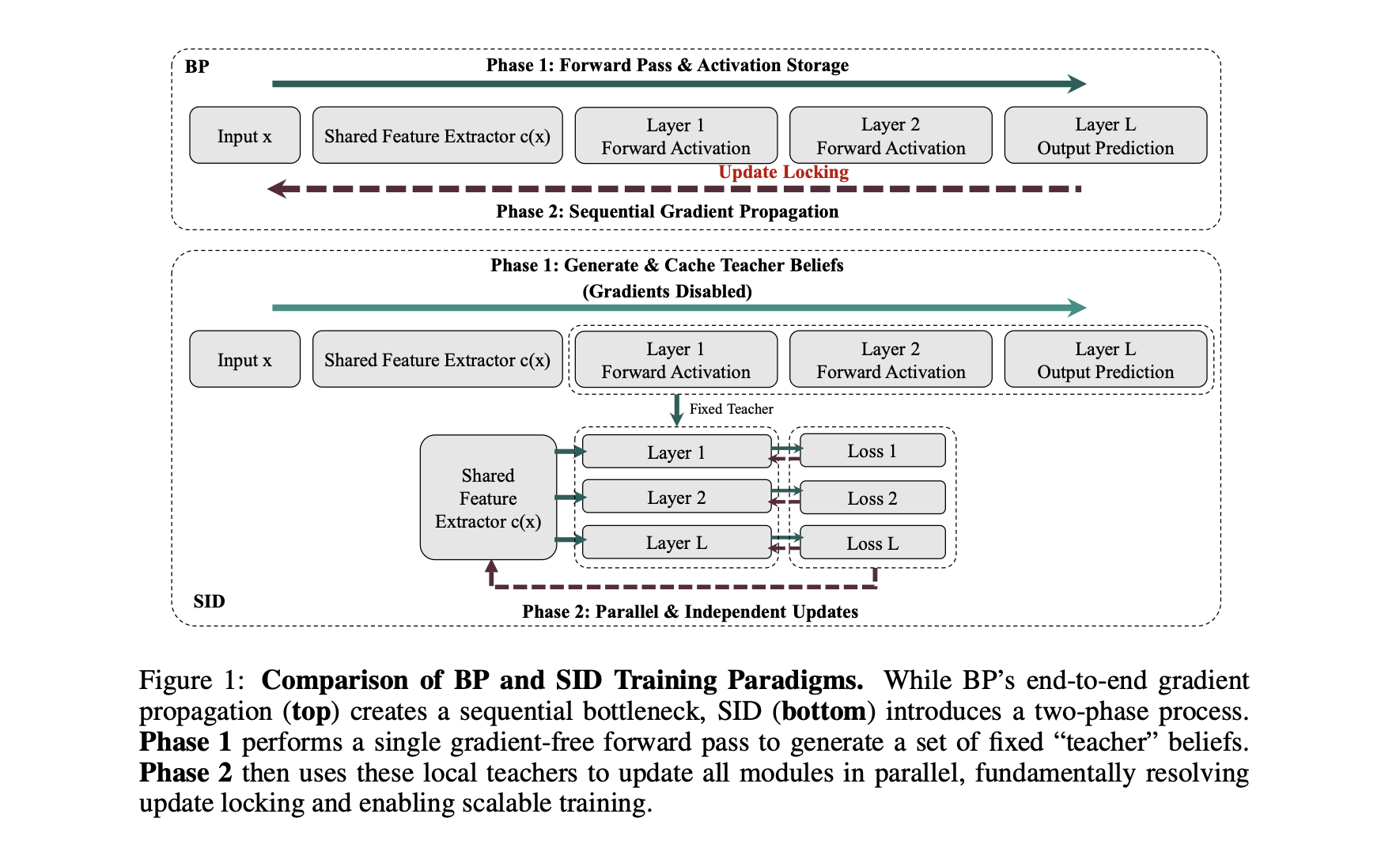
整体结构
1 | 输入 x |
变量说明:
- x: 输入数据(如图像)
- c(x; θ_c): 共享特征提取器,参数为 θ_c,输出特征向量 z
- f_i(·; θ_i): 第 i 个处理模块,参数为 θ_i
- p_i: 第 i 个模块输出的”信念分布”(概率向量),p_i ∈ R^N(N 为类别数)
- p_0: 初始均匀分布 Uniform(N)
模块结构(典型实现)
1 | 输入: (p_{i-1}, z) |
形状变化:
- p_{i-1}: (batch, N)
- z: (batch, d)
- Concat: (batch, N+d)
- Linear: (batch, N+d) → (batch, N)
- p_i: (batch, N)
训练算法流程
SID采用两阶段训练机制,完全消除模块间的梯度依赖。
Phase 1: Teacher Beliefs 生成(无梯度)
目的:生成固定的”教师信念”作为一致性监督目标
1 | with torch.no_grad(): # 关闭梯度计算 |
关键点:
- 整个过程不构建计算图
- 生成的 teacher beliefs 在 Phase 2 中视为常量
Phase 2: 并行模块更新(有梯度)
目的:各模块独立优化,共享特征累积所有模块梯度
1 | # 1. 重新计算共享特征(带梯度) |
参数更新的数学表达式:
模块参数更新(各自独立):
共享特征更新(累积所有模块梯度):
变量说明:
- sg(·): stop_gradient 算子,前向传值、反向截断梯度
- p_y: ground-truth 的 one-hot 编码
- α: 平衡超参数,控制蒸馏项与一致性项的权重
- D_KL(P||Q): KL散度,定义为 $\sum_k P(k) \log \frac{P(k)}{Q(k)}$
- η: 学习率
损失统计与更新
局部损失函数
数学定义:$\mathcal{L}_i(p_{i-1}; f_i) = \alpha \cdot D_{KL}(p_i | p_y) + (1-\alpha) \cdot D_{KL}(p_i | \text{sg}(p_{i-1}))$
两项作用:
Distillation Term(蒸馏项):$ D_{KL}(p_i | p_y) = -\log p_i[y] $($p_y $为 one-hot)
- 拉近模块输出与真实标签
提供主要的监督信号
Consistency Term(一致性项): $ D_{KL}(p_i | \text{sg}(p_{i-1})) = \sum_{k=1}^{N} p_i^{(k)} \log \frac{p_i^{(k)}}{p_{i-1}^{(k)}} $防止当前模块过度偏离前序模块
- 正则化作用,保证渐进式优化
- sg() 阻断梯度:确保 $\frac{\partial \mathcal{L}_i}{\partial \theta_{i-1}} = 0$
Teacher Beliefs 的动态更新
Teacher beliefs 不是固定的预训练模型, 每个 batch 重新生成,随参数更新而改进
1 | Iteration t: |
梯度计算详解
共享特征梯度(长链,串行计算)
假设共享特征为 3 层:z = f_3(f_2(f_1(x; w_1); w_2); w_3)
模块 i 对各层的梯度:
累积所有模块的梯度:
关键点: $\sum_i \frac{\partial \mathcal{L}_i}{\partial z}$ 可并行计算,但 $\frac{\partial f_3}{\partial h_2} \cdot \frac{\partial f_2}{\partial h_1} \cdot \frac{\partial f_1}{\partial w_1}$ 必须串行, 这部分复杂度与 BP 相同
模块参数梯度(短链,可并行)
特点:
- 梯度链路短(仅通过单个模块)
- 完全独立,可在多 GPU 并行计算
text 1
2
3
4
5
6
71. 计算 z = c(x; θ_c^(t)) ← θ_c 固定在当前值
2. 并行计算(θ_c 不变):
GPU 1: z → p_1 → L_1 → ∂L_1/∂θ_c
GPU 2: z → p_2 → L_2 → ∂L_2/∂θ_c
GPU 3: z → p_3 → L_3 → ∂L_3/∂θ_c
3. 汇总:g_c = Σ ∂L_i/∂θ_c
4. 更新:θ_c ← θ_c - η · g_c
时间复杂度
- 传统 BP(单分类头): $ T_{BP} = T_{\text{feat fwd}} + T_{\text{cls fwd}} + T_{\text{cls bwd}} + T_{\text{feat bwd}} $
- SID(多模块): $ T_{SID} = T_{\text{feat fwd}} + \max_i T_{g_i \text{ fwd}} + \max_i T_{g_i \text{ bwd}} + T_{\text{feat bwd}} $
- 理论加速:如果 $\max_i T_{g_i} < T_{\text{单分类头}}$,可能更快,但增加了额外模块计算,未必总是更快
论文实测:在理想并行条件下,加速 2-3倍
内存复杂度
BP 内存需求: $ M_{BP} \approx \sum_{i=1}^{L} A_i \quad \text{(存储所有层激活)} $
SID 内存需求: $ M_{SID} \approx \max_i A_i + \sum_{i=0}^{L-1} |p_i| \quad \text{(单模块激活 + teacher beliefs)} $
实际节省:
- CIFAR-100 实验:150 MB → 1.25 MB
节省 120 倍
原因:Teacher beliefs 只是概率向量(小)
- 只需存储当前模块激活
- 不需要存储中间层的完整特征图
收敛性保证
理论保证(Proposition 2): $ D_{KL}(p_L | p_y) \leq D_{KL}(p_0 | p_y) - \frac{1-\alpha}{\alpha} \sum_{i=1}^{L} D_{KL}(p_i | p_{i-1}) $
最终预测与真实标签的距离 ≤ 初始距离 - 累积改进量,所以只要每层满足 $\mathcal{L}_i(p_i) \leq \mathcal{L}_i(p_{i-1})$(局部改进)就能保证全局性能单调不退化
- Distillation:向正确答案靠近
- Consistency:不偏离前序信念太远
- 两者平衡 → 稳定收敛