引言:岭回归及其闭式解
在实际的数据科学中,我们经常遇到病态(ill-conditioned)的数据矩阵,即设计矩阵 $\mathbf{X}^T\mathbf{X}$ 的条件数很大,导致最小二乘估计对噪声极其敏感。这种情况在高维数据、共线性特征或样本量不足时尤为常见。病态问题会导致模型参数估计不稳定、方差过大,最终造成过拟合。
岭回归(Ridge Regression)作为一种正则化方法,通过在目标函数中添加 $L_2$ 惩罚项来缓解病态问题。本文旨在深入探讨:
- 岭回归如何在病态条件下发挥作用:从数学角度分析正则化参数 λ 如何改善矩阵的条件数,抑制噪声方向的影响
- 正则化强度 λ 的权衡:研究 λ 在降噪和参数估计准确性之间的平衡关系
- 梯度法求解岭回归的收敛性:当直接求解闭式解不稳定时,探索 Armijo 策略下不同参数对梯度下降法收敛速度的影响
通过理论分析和数值实验,本文将展示岭回归在处理病态问题时的有效性,并为实际应用中参数选择提供指导。
考虑岭回归问题:
其目标函数为:
为获得闭式解,对目标函数求导并令其为零:
求解 $\mathbf{w}_\lambda$ 得到闭式解:
注意到解的存在性依赖于 $\mathbf{X}^T\mathbf{X} + \lambda\mathbf{I}$ 的可逆性。当 $\lambda > 0$ 时,该矩阵正定,因此必然可逆,解总是存在且唯一。当 $\lambda \leq 0$ 时,矩阵可能不正定,但若 $\mathbf{X}^T\mathbf{X} + \lambda\mathbf{I}$ 的所有特征值非零,解仍然存在。
通常情况下,我们取 $\lambda > 0$,以提供 $L_2$ 正则化惩罚来控制过拟合,此时解总是存在且唯一。
本文采用人工构造的数据集进行实验,数据生成代码如下:
1 | import numpy as np |
在演示中,我们取 λ = 1.2, α = 0.5, β = 0.5。参数 λ = 1.2 经过详细分析(见后续讨论部分)被确定为最适合本问题的值。而 α 和 β 的值简单地设为其有效范围 [0, 1] 的中点,无特殊含义。
对于闭式解,我们直接应用公式:
同时,我们也应用了配合Armijo规则的梯度下降法,得到如下结果。
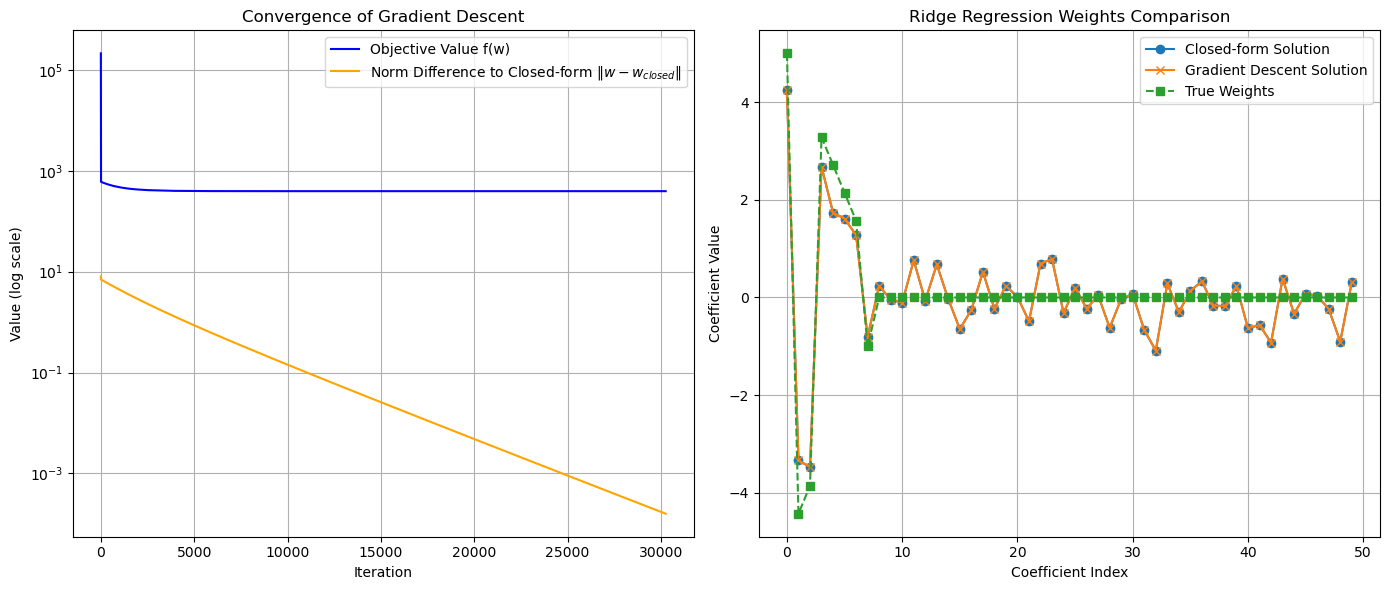
左图展示了目标函数随梯度下降算法的变化趋势。可以看到,尽管后期下降幅度不显著,但目标值保持递减,体现了线搜索策略的有效性。同时,我们的预期也得到验证:由于该问题是凸优化问题,梯度下降算法的参数 w 收敛于闭式解 w_closed form。黄色曲线表示 w 与 w_closed form 的范数差异,可见其持续收敛。右图展示了参数结果,w_GD 的结果与其闭式解非常接近,肉眼几乎无法区分。而 w_closed form 也较好地拟合了原问题中的真实参数,对模型具有良好的解释力。
正则化强度 λ 的影响
不同 λ 下的 $\|\mathbf{z}-\mathbf{z}_{\text{true}}\|$ 分析
下图展示了估计权重与真实权重差异的范数与正则化参数 λ 的关系。
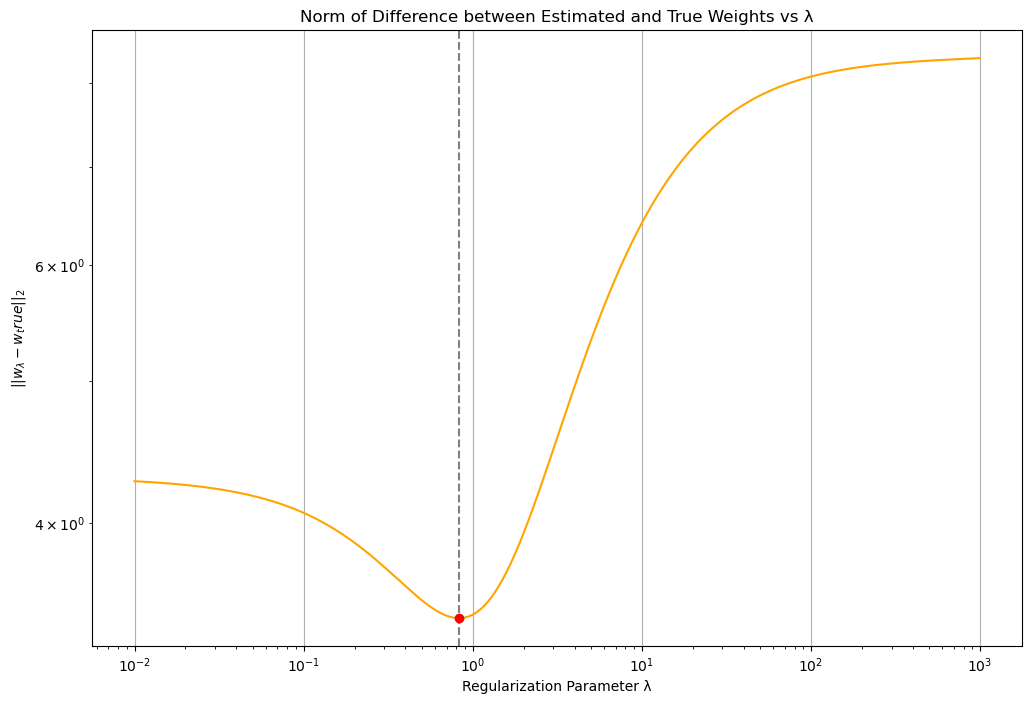
这里我们在对数尺度上对 λ 进行采样。整体而言,λ 较小时表现优于 λ 较大的情况。放大观察 0 到 10 的区域,最低点出现在 λ = 0.82 处,值为 3.44。但观察 w_true 的真实分布后,由于 w_true 只有前 8 维是有效的,因此从分布相似性角度,分别分析前 8 维和后续维度的范数差异是有必要的:
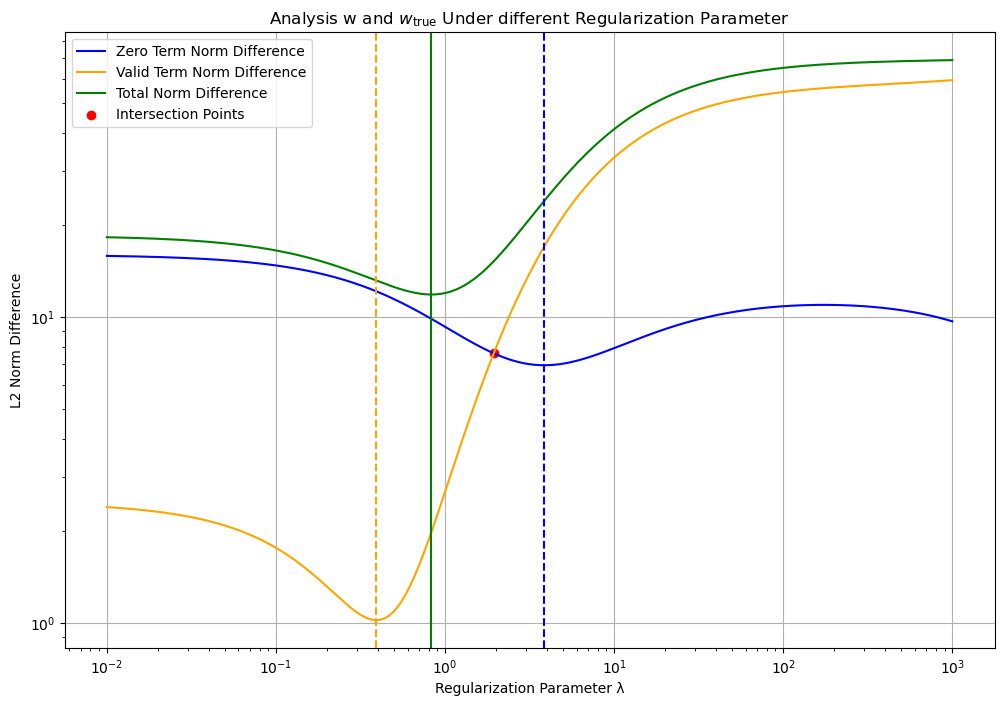
这里我们分别度量了前 8 维和后 42 维,统计各自表现最佳的正则化强度。结果显示:λ = 3.84 时,优化结果在抑制噪声方面表现最佳;λ = 0.39 时,对主要参数(前 8 维)的恢复最准确。这反映了正则化强度实质上是在降噪和估计真实参数之间寻求平衡。在这两个极端状态下,我们发现之前全参数范数的最优解 λ = 0.83 正好位于 0.39 和 3.84 之间,是一种平衡两者的选择。事实上,我们还可以找到一个特殊的交点,即黄色和蓝色曲线的交点 λ = 1.94。尽管度量范数不一定完全代表对真实参数的相似性测量,但这个点也可作为两者平衡的状态。实际上,在后续对 MSE 的观测中,这两个点确实提供了对模型的良好估计。
为了找到降噪和真实参数估计之间的平衡,我们还可以通过数学推导进行定性分析。在最小二乘模型中:
根据 SVD 分解,设 $X = U\Sigma V^T$,其中 $U \in \mathbb{R}^{n \times n}$,$\Sigma\in \mathbb{R}^{n \times p}$ 是奇异值的对角矩阵,$V \in \mathbb{R}^{p \times p}$,其中 $\lambda(\mathbf{X}^T\mathbf{X})=\sigma _i^2(\mathbf{X})$,即奇异值由 $[X^TX]$ 的特征值得到,且 $U, V$ 都为标准正交矩阵。
由以下推导:
因此:
进而:
转化为向量形式:
将噪声代入表达式:
注意到对于当前问题的 $\mathbf{X}$,我们计算了 $X^TX$ 的条件数高达 14436.20,且大量特征值都在较小的数值范围内。我们知道,当奇异值较小时,对应的特征向量方向包含的信息较少,此时噪声占主导地位,应被忽略;而特征值大的方向包含了更多模型的真实信息。然而,当我们对这些特征值进行倒数处理时,真实信息方向对应的值会因为大特征值而减小,而噪声方向的值会因为小特征值而被放大。求解器无法很好地区分噪声方向和真实信息方向,导致该问题使用简单的最小二乘算法会受到严重的噪声干扰,进而导致模型过拟合。
而引入 L2 正则化策略后,我们有:
当特征值很大时,$\frac{\sigma_i}{\sigma_i^2 + \lambda} \approx \frac{\sigma_i}{\sigma_i^2}$ 与最小二乘估计保持一致,确保模型信息;当特征值较小时(与 $\lambda$ 相近),明显有 $\frac{\sigma_i}{\sigma_i^2 + \lambda} \leq \frac{1}{\sigma_i}$,起到阀门作用,抑制噪声主导的方向。λ 越大,对噪声的抑制力度就越大。但正则化力度过大的代价是:结果成为对真实参数的有偏估计。具体而言,我们知道最小二乘的结果是对模型参数的无偏估计,即 $E[\mathbf{w}_{LS}] = \mathbf{w}_{\text{True}}$。
注意到当 $\lambda \rightarrow 0$ 时为最小二乘问题,是无偏估计;但随着 $\lambda$ 增大,就会与真实结果差距过大,导致模型欠拟合。总结如下:
- $\lambda \rightarrow 0$:趋向于对真实参数的无偏估计,但易受噪声干扰,模型过拟合
- $\lambda \rightarrow \infty$:抑制噪声干扰,但会偏离对真实参数的回归,模型欠拟合
接下来我们将分析模型的 MSE 来验证与补充上述结论。
MSE 分析
下图描述了模型在不同正则化强度下的训练和测试误差。我们捕捉到关键点:在 λ = 1.2027 时测试集误差达到最小。在之前对 w_true 的范数差异分析中,我们得到了两个平衡噪声和参数估计的点(0.8276 和 1.9410),而真正的测试最低 MSE 也在其附近,这说明上述结论的估计是合理的。同时也再次说明,范数上的最小化并不一定代表优化参数和真实参数最相似。
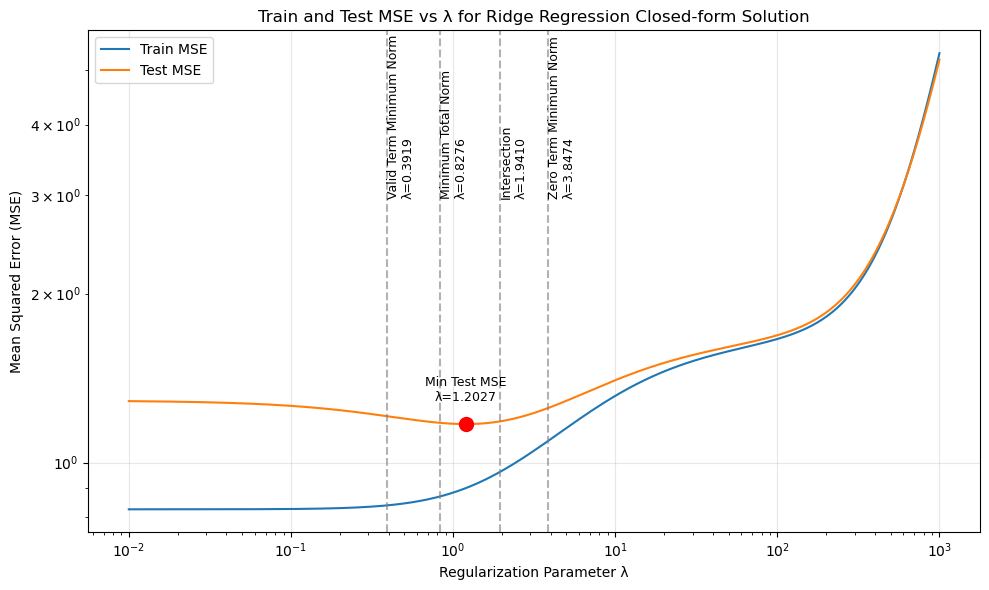
从整体上看,随着 λ 的减小,测试 MSE 曲线呈现上升趋势,说明确实出现了过拟合现象;而当 λ 较大时,模型拟合程度不够。这与之前的分析一致。
不同 α 和 β 下的收敛速率
在常见的计算算法中,当数据集规模变大时,直接计算闭式解相对来说不太稳定。这时梯度法是一个合理的选择:
1 | Algorithm 2: The Gradient Method |
为探究不同线搜索策略变量如何影响收敛,我们固定 λ = 1.2 进行实验。当 λ > 0 时,我们知道 $[X^TX + \lambda I] > 0$,所以该优化问题为在 $\mathcal{R}^p$ 上的凸优化问题,使用梯度下降法必然收敛至唯一解 $\mathbf{w}_{\text{closed}}^*$。
实验 1:固定迭代次数 Epoch = 1e5 下的收敛研究
我们将初始学习率设为 s = 1 进行迭代,记录参数优化序列 $\{\mathbf{w}_i\}_{n=1e5}$ 以及优化后梯度的大小。为确保程序流畅执行,我们在 Armijo 循环内施加约束 $t_k < 10^{-16}$ 以防止无限循环。
1 | while not Armijo Ineqn Condition: |
第一个实验针对每个参数对 $(\alpha, \beta)$,我们运行梯度下降法至 epoch=10000,绘制 $(\alpha, \beta)$ 关于 $-\log{\|\nabla f(\mathbf{w_n})\|}$ 的热力图以及目标函数的变化图:
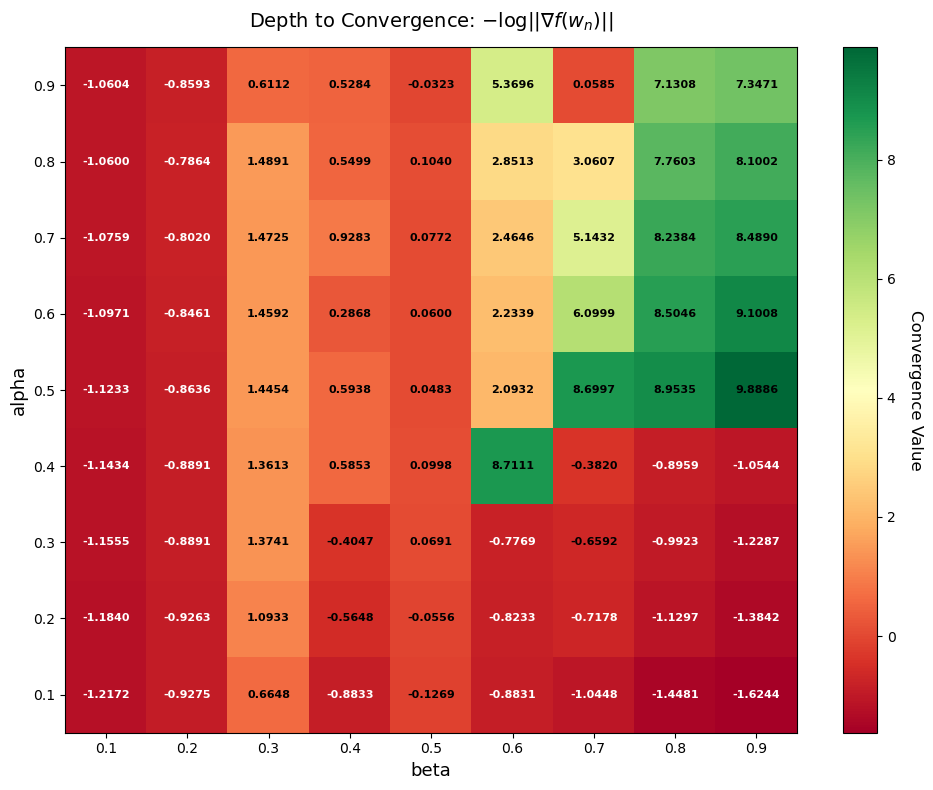
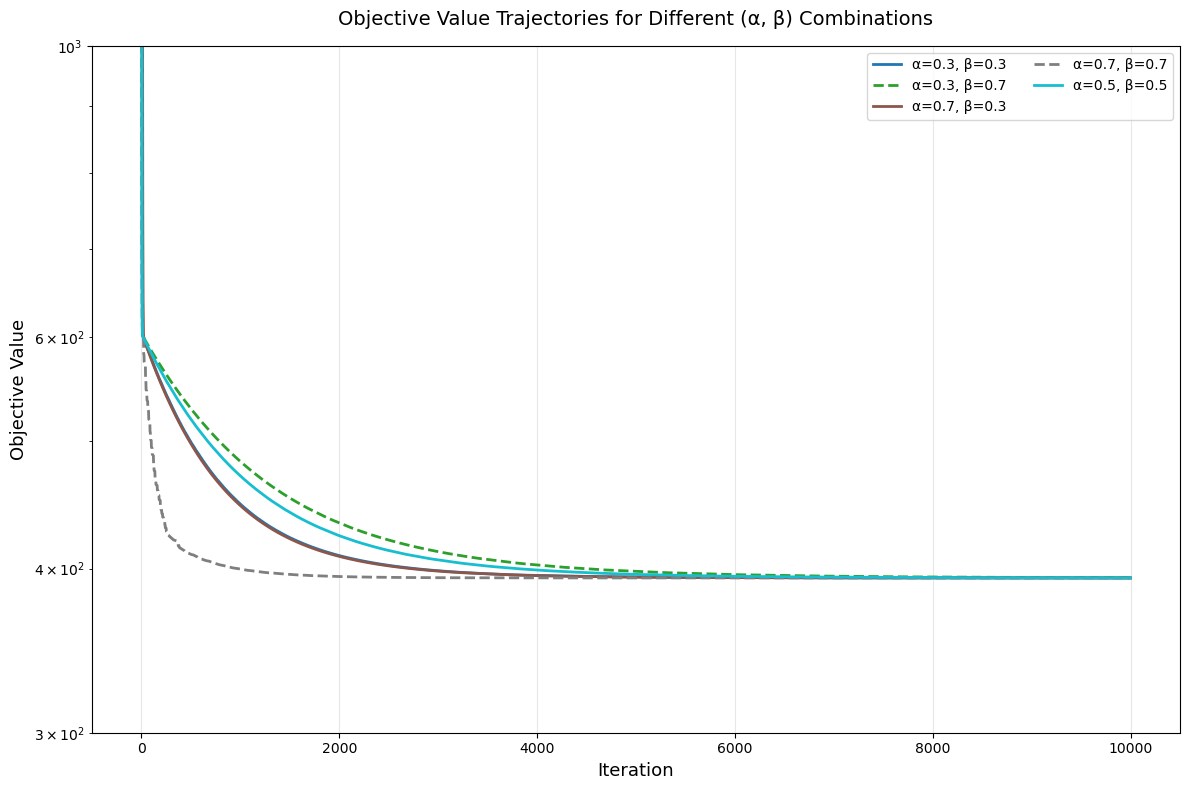
对于目标函数图,我们采样了 5 个点。注意到所有点最终能使函数收敛到的结果基本一致,而 α = 0.7 时的收敛速度优于 α = 0.3;对于 α = 0.7,β = 0.7 的收敛速度最佳。因此我们推测相对而言较大的 α 收敛速度最快,同时配合较大的 β 可以让收敛速度最优。尽管从目标函数的数值上我们很难比较不同参数对的收敛效果差异,我们进一步通过分析此时目标函数的梯度值来讨论。
从热力图可以观察到,整体上 $\alpha, \beta$ 的大小与收敛程度呈现明显的区域分化,且沿着对角线方向向右上方收敛效果变好:
- 右上方区域($\alpha \in [0.5, 0.9]$ 且 $\beta \in [0.6, 0.9]$):右上角区域收敛情况较好,同时注意到该区域整体上在 α = 0.5 这条线上收敛情况最佳,相同 β 下 α 越接近 0.5 梯度越小
- 右下方区域($\alpha \in [0.1, 0.5]$ 且 $\beta \in [0.6, 0.9]$):除了 (0.4, 0.6) 表现突出,其他部分均收敛失败
- 左部区域($\beta \in [0.1, 0.3]$):未收敛,不论 α 如何取情况都较为相似,梯度范数均未降到 1 以下
- 中部区域($\beta \in [0.3, 0.5]$):β 的取值在一定程度上可以收敛,大部分都收敛到梯度范数 1 以下,注意到整体依然以 α = 0.5 附近为中轴线,越远离 α = 0.5 收敛情况越差
我们可以从 Armijo 策略来解释上述现象。使用该策略是为了保证模型每次迭代的收敛力度,同时使步长尽可能大。从定性角度,α 越大意味着 Armijo 不等式条件更加严格,需要找到使目标函数下降更强的步长;而 β 决定了每次更新学习率的幅度。
在当前案例中,表现最好的区域符合直觉:高 β 高 α 意味着严格的下降程度和细致的 β 搜索。小幅度的步长变化可以确保找到最优步长,严格的下降程度意味着每次都能有效迭代,进而体现出良好的收敛结果。接下来我们对 α 的选择进行分析:

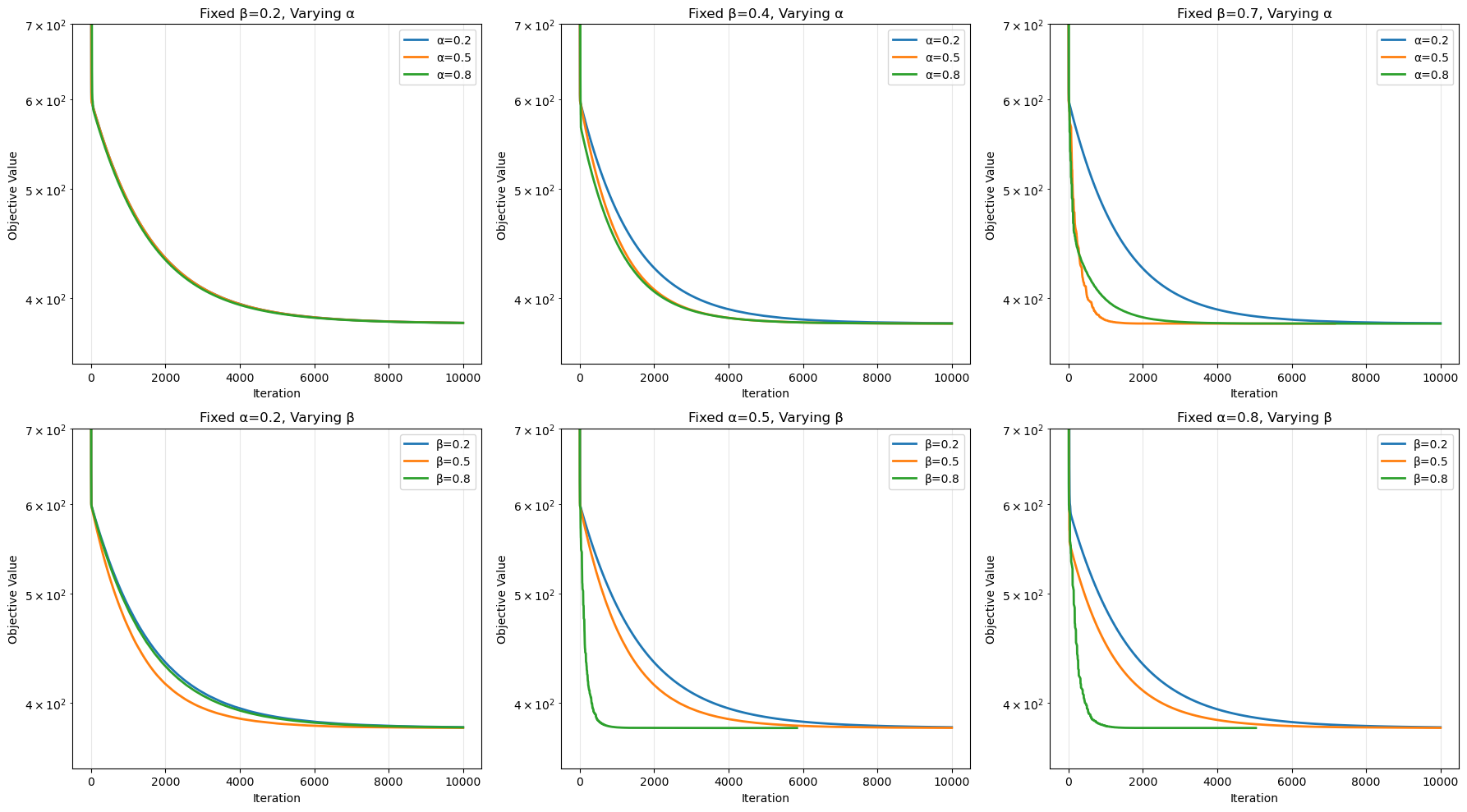
上图展示了 6 个不同 α 下的收敛趋势图,每个图中我们采样了 4 个 β 值下的梯度变化序列作为数据。可以观察到 α = 0.5 的图是一个分水岭,每张图中四个对象的收敛效率从红绿黄蓝的顺序渐变至黄蓝绿红,不同 β 值的梯度震荡也发生变化。对此我们提出如下解释:
当 α 较小时,Armijo 条件松弛,每次梯度下降的下降量并不充分。可以看到尽管在前两张图中,四种颜色有所差异,但观察其梯度下降的量级都在 1 附近,没有明显差异,这时 α 主导收敛趋势,β 的差异体现得并不明显;
当 α 较大后,每次梯度下降的力度变大,这时能否找到一个尽可能大的学习率就显得尤为重要。我们注意到 β 越大,能够确保每次搜索到的 t 尽可能大,使其收敛速度快,同时在 t 较大时,两次迭代之间 w_k 和 w_{k+1} 距离较大,导致了较大幅度的震荡。
下图展示了若干 α 下收敛度关于 β 的曲线。这也可以证明上述结论:对于 α 较小时(line α = 0.3 和 0.4),尽管折线有波动,但收敛力度始终没有超过 1e-2 这条线,只有在 α 较大时,才有机会通过微调 β 使其进行有效的梯度下降,冲击高收敛效果。
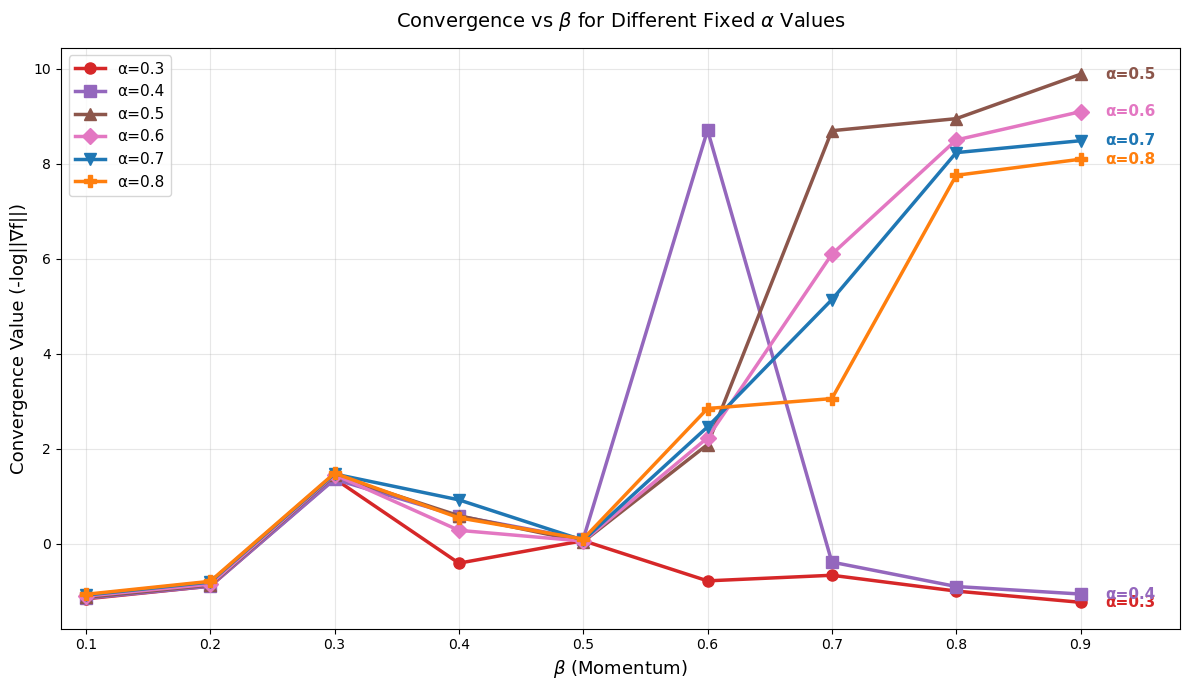
同时我们还需要用这个图来阐述 β 的选择如何影响算法。可以看到在高 α 值曲线(0.5-0.8,α = 0.9 时下降条件过于苛刻不做讨论)均在 β = 0.9 时达到最大值,这符合直觉,因为保证较大的步幅对收敛有利。但这背后有一个潜在问题:如果我们把参考迭代次数从每次计算 w_{k+1} = w_k + t_k * d_k 换成总计算循环次数(梯度下降更新 + 线搜索循环),大 β 值会让步幅变化过于保守,导致较高的线搜索开销,这时适当减小 β 值会是更有利的策略,这一点我们会在下一个实验中进一步分析。我们还注意到特殊点 (0.4, 0.6):尽管对于 α = 0.4 时整体收敛较差,但配合 β = 0.6 就会让算法焕然一新,这似乎可以归结为适应该问题目标函数的奇迹般的耦合点。
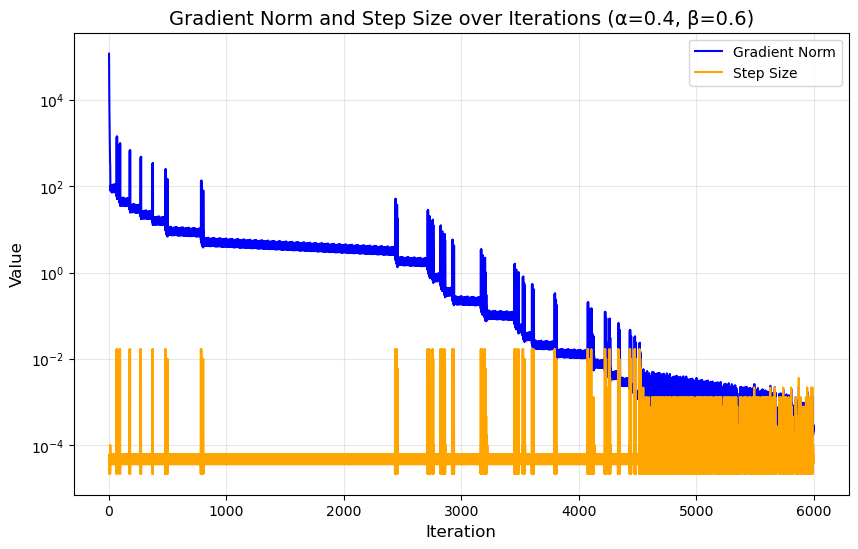
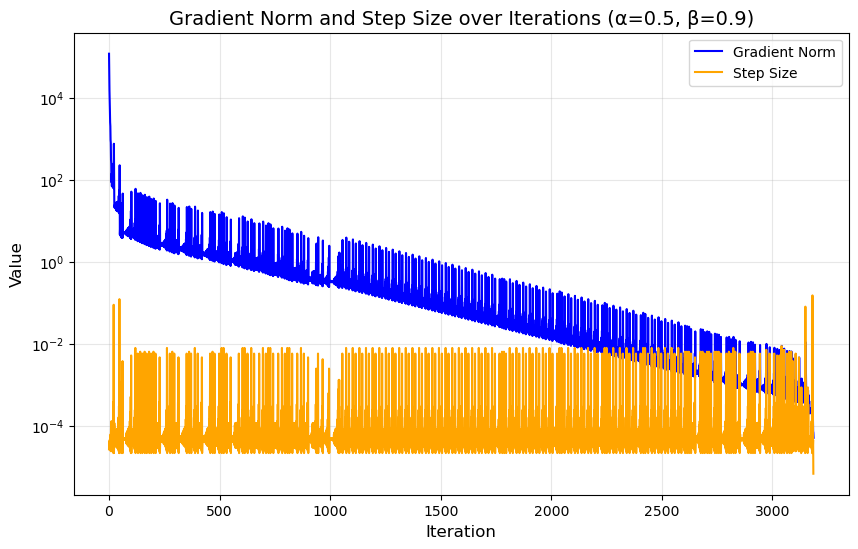
进一步看,绘制出 α = 0.4, β = 0.6 这组参数的收敛曲线令人惊讶。不同于右侧 (0.5, 0.9) 典型的大振幅持续有规律的下降,这组参数的步长曲线几乎是完全平坦的水平线(除了初始阶段和个别跳跃点),好似正好找到了一条最均匀的下降路径,同时震荡情况在很多状态都未出现。我们可以得出结论:尽管从常识上,大 α 大 β 可以使梯度下降有效进行,但也存在某些特殊的参数对,恰好在下降条件的严格性和步幅变化幅度中找到平衡,是”恰到好处”的巧合组合。
最后,我们绘制目标函数的变化,看看是否与上述结论一致:
可以发现这与之前分析参数对的结果完全一致:α 较大时,β 值主导收敛,β 越大收敛越好;当 α 较小时,α 主导收敛,整体效果上限较弱,且 β 对收敛影响较小。
实验 2:固定容差 Tol = 1e-3 下的收敛验证
接下来我们将控制变量从固定 10000 epoch 变为梯度收敛至固定容差 tol=1e-3,通过检查使用的 epoch 次数和总循环数来验证上述结论。注意到在 α = 0.9 时,出现了几处空白,这是因为在线搜索中出现了步幅过小的问题,归因于 α 使下降要求过高导致的数值不稳定。
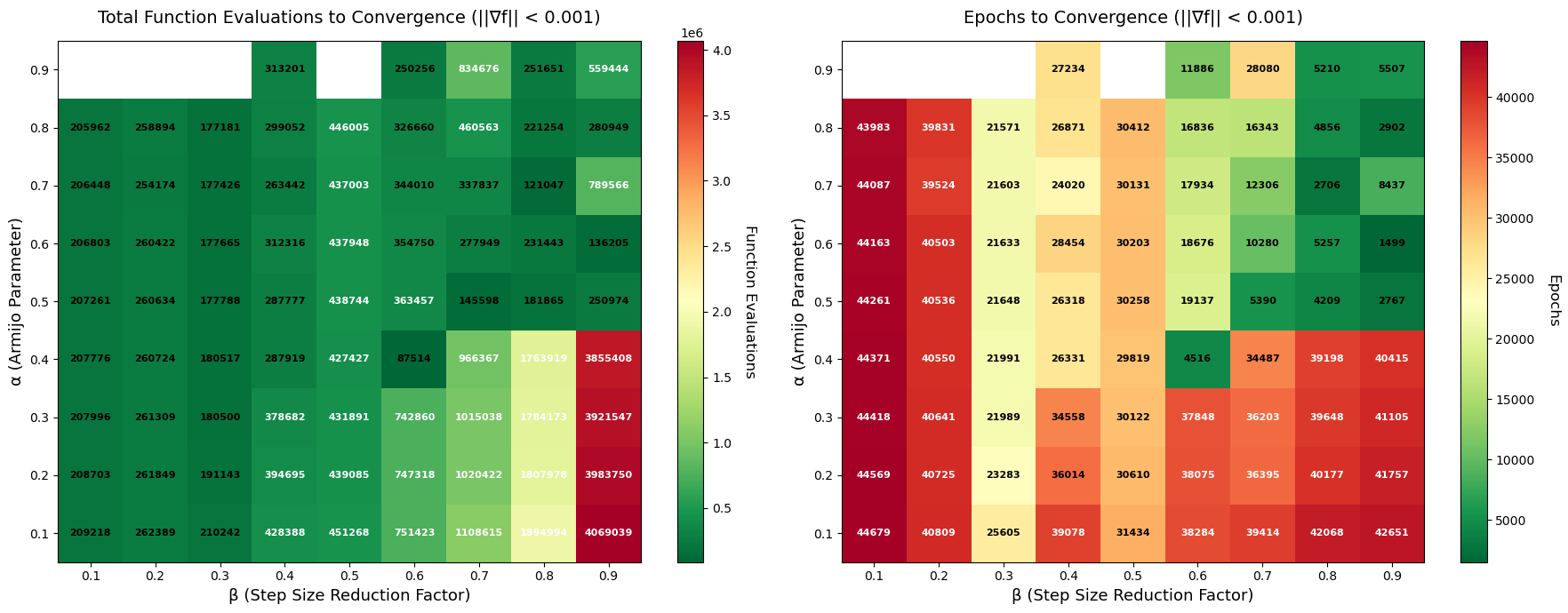
首先我们关注梯度下降循环的 epoch 数,这个图与上面固定 epoch=10000 下各点收敛情况一致,依然呈现出小 β 和右下角收敛效果弱、中部递增、右上角最强的区域性分布。但当我们统计总循环开销时,情况发生变化:右上角尽管有优势,但与 β 较小时差异不大,说明从计算开销角度,小 β 能更快达到符合 Armijo 条件的步幅,这弥补了其每步 w 移动较小的劣势;而对于右下角则更加糟糕,缓慢的线搜索搭配不充分的下降使其在总开销上表现糟糕。对于近似的 epoch 收敛情况,我们上面说过适当减小 β 值会是更有力的策略。可以看到 (0.8, 0.6) 和 (0.8, 0.7) 两者收敛到 1e-2 的 epoch 数都约为 16000,但其总循环数差了 1e5 次,说明平均每次梯度下降,β = 0.6 都比 β = 0.7 少约 8 次线搜索迭代。令人震惊的依然是 (0.4, 0.6) 不仅在 epoch 数上表现优异,在总计算数上更是降到了 1e6 以下,大幅领先其他参数对。我们认为这个特殊点就是对该问题最合适也最巧合的参数选择。进而我们可以有一下归纳:
从执行
w_{k+1} = w_k + t_k * d_k的 Epoch 数角度,如果需要让 Armijo 条件有效控制函数数值的下降,较大的 α 是合理选择;同时每次下降的步幅期望尽可能大,进而较大的 β 可以保证有效收敛。整体上大 α 和大 β 配对是合理的,但参数选择不应使用贪心思想,而是通过微调参数实现动态平衡。在本案例中,$(\alpha, \beta) = (0.4, 0.6)$ 就是这样一个达到动态平衡的点。从总计算开销来看,如果假设各种计算操作的复杂度相似,那么只要不是小 α 搭配大 β,在总计算开销上差异性不大。大多数时候 epoch 数量和线搜索循环的效率会形成互补关系。在本案例中,动态平衡点 (0.4, 0.6) 为收敛效率最高点。
总结
本文系统地研究了岭回归在病态条件下的表现,以及使用 Armijo 策略的梯度法求解岭回归问题的收敛特性。主要结论如下:
岭回归对病态问题的改善机制
通过 SVD 分解分析,我们揭示了岭回归的本质作用机制:
- 病态问题的根源:当数据矩阵 $\mathbf{X}^T\mathbf{X}$ 条件数很大(本文实验中达到 14436.20)时,小奇异值对应的方向会因倒数运算而被放大,导致噪声主导这些方向,造成过拟合
- 正则化的改善作用:引入 $\lambda$ 后,权重更新公式变为 $\frac{\sigma_i}{\sigma_i^2 + \lambda}$,对小奇异值方向起到”阀门”作用,抑制噪声影响,同时保留大奇异值方向的真实信息
正则化强度 λ 的权衡
λ 的选择体现了偏差-方差权衡:
- λ 过小:趋向无偏估计,但易受噪声干扰,导致过拟合
- λ 过大:有效抑制噪声,但偏离真实参数,导致欠拟合
- 最优选择:实验表明 λ = 1.2027 在测试集上达到最低 MSE,这个值位于纯降噪最优点(λ = 3.84)和参数恢复最优点(λ = 0.39)之间,实现了两者的平衡
Armijo 策略下梯度法的收敛特性
对于梯度下降法配合 Armijo 线搜索策略,我们发现:
- α 的作用:控制下降条件的严格程度,较大的 α 要求每次迭代有更显著的函数值下降,是有效收敛的必要条件
- β 的作用:决定步长缩减的幅度,较大的 β 意味着更保守但更精细的步长搜索
- 参数耦合效应:大 α 和大 β 的组合通常表现良好,但存在特殊的”平衡点”,如 (α=0.4, β=0.6) 在本问题中表现出奇迹般的收敛效果,震荡小、收敛快、计算开销低
- 计算效率权衡:虽然大 β 有助于单次迭代的效果,但会增加线搜索的计算开销;适度减小 β 可以在总体计算效率上取得更好的平衡
实践启示
本研究为实际应用提供了以下指导:
- 正则化参数选择:应通过交叉验证在测试集上寻找最优 λ,而非简单地最小化训练误差或参数范数差异
- 梯度法参数调优:在使用 Armijo 策略时,不应盲目追求大 α 和大 β,而应根据具体问题通过网格搜索或贝叶斯优化寻找平衡点
- 病态问题诊断:当数据矩阵条件数很大时,正则化几乎是必需的,即使在样本量充足的情况下
总之,岭回归通过引入正则化有效地改善了病态问题,而合理选择优化算法的参数能够在保证收敛质量的同时提高计算效率。理解这些方法背后的数学原理,有助于我们在实际问题中做出更明智的决策。